CONDOC stands for ‘connections document’. This document is used when you want to enhance other people’s content. A CONDOC does not contain primary content of its own. Instead, it specifies:
A reference to an external “main” document.
A set of outbound connections to additional documents. Connections may contain floating links.
2. Structure
A CONDOC document consists of the following top-level elements:
<connections> <doc url="https://reinventingtheweb.com/examples/famous-men/table-of-contents.hdoc" title="Table of contents of the Project Gutenberg eBook "Famous Men of the Middle Ages"" hash="1f25bd"> i:25422;l:19;h:60e455;e:QUg=_i:5;l:19;h:3c1f60;e:QWg= i:33104;l:14;h:df0913;e:QU4=_i:43;l:14;h:457c77;e:QW4= ... </doc> </connections>
</condoc>
5. Example CONDOCs
To view working examples, install the Visible Connections browser extension and open the following files:
Let’s say you want to connect your page to another page on a different website. There’s a problem: that other site doesn’t support HDOCs. Can we work around that? It turns out yes, we can. HDOCs are very simple. They’re basically a title and the content (plus a few optional fields). If you can locate those two things on a page, you can build an HDOC locally even if the original page isn’t an HDOC.
In other words, we need to be able to parse arbitrary web pages. But all client apps must parse them the same way. If they don’t, you’ll end up in a situation where a floating link works in one app and looks broken in another. And you won’t be able to fix it, because the underlying text is slightly different depending on how each client parsed the page. We need deterministic parsing. That’s where parsing rules come in.
Here’s what a URL with parsing rules may look like:
Everything after #pr= is the parsing rules section. It’s a set of key–value pairs where each value is a selector. Most of them are optional. The only required one is the content selector. Because of that, for many pages URLs with parsing rules will look much simpler, for example:
https://example.com/some-page#pr=c/body
Here are all the supported selectors:
c — content selector (required)
t — title selector (optional if the title is in an <h1> and is unambiguous)
r — list of selectors to remove from the final content (optional). Multiple selectors are separated by commas. Each selector is URL-encoded individually.
d — publication date selector (optional)
a — author name selector (optional)
All selectors must be URL-encoded.
Behind the scenes, a client app simply calls querySelector with the selector you provided. For the “remove” list, it calls querySelectorAll.
How to find selectors using the LZ Desktop app
If you use the LZ Desktop app together with the LZ Desktop Helper Chrome extension, you can download pages directly from your browser. For some websites (currently only English Wikipedia and Gutenberg.org), downloaded pages already include parsing rules in their URLs. For most sites, though, the app relies on a text-density parsing library that tries to guess where the main content is. The problem: pages parsed this way cannot be used as connected pages. You can view them locally and even create visible connections, but if you publish them, nobody—including you—will see those connections when viewing the page online. That’s intentional and prevents the “different clients parse differently” issue that breaks floating links.
Your first step should be to right-click the downloaded page and choose “Download using parsing rules.” The app downloads the page again, but this time it doesn’t analyse text density. Instead, it goes through a predefined list of selectors and uses the first one that matches something meaningful on the page. This approach works about 50% of the time. Sometimes you’ll get clean parsing rules; sometimes the page will look broken. In the broken cases, you’ll need to create parsing rules manually.
By the way, this is exactly why LZ Desktop uses two parsing methods: the automatic one is more reliable for personal reading, and the deterministic one is necessary for publishing visible connections.
How to find selectors manually
If LZ Desktop didn’t help—or you don’t want to use it—you can always pick selectors yourself.
Open the page in Chrome.
Open Developer Tools (View > Developer > Developer Tools).
Use the “select element” arrow to inspect the page.
Locate the element that contains all the real content (without comments, navigation, ads, etc.).
Check its classes, IDs, or anything else that could work as a selector.
If you’re unsure about selector syntax, ask ChatGPT. Show it relevant pieces of HTML and ask what selectors you can use in querySelector method.
You can also open the LZ Desktop Helper popup, click “Configure URL”, and type your parsing rules there. The extension will handle URL encoding. Then you can download the page into LZ Desktop using those rules. Through trial and error you’ll eventually discover the right set.
Sometimes this is easy. Sometimes it’s frustrating. And some pages are effectively impossible because all the classes are machine-generated nonsense.
Good news
Once you figure out the parsing rules, every client will parse the page identically. Users won’t even know parsing rules exist—everything “just works.” Only the author suffers during setup.
Another bit of good news: for many websites, the same parsing rules work across all pages. If you use the LZ Desktop Helper extension, you can configure site-wide rules, and every page you download from that site will automatically use them.
In the future we may create a public database of parsing rules for different websites which may be integrated with the extension, so you won’t have to come up with parsing rules that often, especially for the more popular websites.
And over time—this is the optimistic scenario—HDOCs become common enough that parsing rules aren’t needed as often.
Special cases
A special parsing rule exists for plain-text pages:
https://example.com/some-page#pr=text
Here "text" means the page is plain text and should be treated as such. Also, if the parser finds a line starting with Title: ..., it treats it as the page title in this case.
There are also two WordPress-specific parsing modes:
WordPress powers roughly 40% of the web, and most WP sites expose a public API. Using that API we can get clean content that isn’t polluted by themes and plugins. HDOCs generated this way may even include comments with pagination. These keywords (wppage and wppost) tell the client to use the API instead of scraping the original HTML.
The client app will call URLs that look like this:
How do you know if you can use wppost or wppage for a given web page?
When you choose “Download with parsing rules” in LZ Desktop, the app first pretends the site is WordPress and tests its APIs. If the request succeeds, the newly downloaded page will contain #pr=wppage or #pr=wppost in its URL. If the request fails, the app falls back to selecting possible CSS selectors, as described earlier.
Using WordPress APIs may feel like a hack, but it may save a lot of work. And if HDOCs ever become popular enough, WordPress could start supporting them natively (right now you need a plugin), the same way it ships with built-in RSS support. If that happens, client apps will be able to ignore wppage and wppost entirely and simply load the HDOC directly from the URL.
I originally designed HDOC as a standalone document format. In the future, when browsers and search engines support it natively, many HTML pages could be replaced with HDOCs. In most cases, the real content is stored in a database anyway, and changing the presentation layer is trivial. The problem is that right now, neither browsers nor search engines know anything about HDOCs. If you replace your HTML pages with HDOCs today, your site basically disappears for most people.
One way around this is to serve HDOCs from separate endpoints. That lets you keep the original HTML page, but now you’re maintaining two URLs for essentially the same content. It would be much better if you could serve both the HTML page and the corresponding HDOC from a single URL. That’s exactly what the embedded HDOC format is for. It lets you embed an HDOC inside your HTML page.
Which version a person sees depends on the software they use. Most visitors will just see the HTML page. Anyone with HDOC-aware software will see the HDOC version instead.
To embed an HDOC into an HTML page, you need to do two things:
Mark the element containing the page’s actual content with a special class called hdoc-content.
Add a <script> tag with JSON content and the id hdoc-data that includes all the additional information needed to construct the HDOC locally.
A client app will download the full HTML page, extract the content from the marked element, then read everything else from the JSON. With that information it can construct an HDOC—served from the exact same URL as the original HTML page.
The "removal-selectors" field is useful if some plugin has polluted your content with unnecessary elements. You can list selectors that HDOC-aware software should remove from the final content.
You don’t need the metadata field if all you want is the page title. The client software will automatically use document.title from the HTML page.
There may be other fields not described here. This format is still a draft, and I’ll make this and the other data formats more official in the near future.
My WordPress plugin already supports embedded HDOCs. Once installed, it handles everything for you: marking the content, generating the JSON, and injecting it into the page. If you want, you can also define site-wide information in the plugin’s settings, and it will automatically include it in the JSON.
The best part is that your site looks exactly the same as before to most people. You don’t need extra endpoints or duplicate pages just to make HDOCs available.
I’ve recently made some significant updates to the project.
Updates to the HDOC Format
First of all, I’ve updated the HDOC format. You can view the latest format description here. The visible title now sits in the header section along with other visible metadata like the author and date — separate from the content. Changes in the header section no longer break floating links that may exist in the content section.
Parsing Arbitrary Web Pages
It’s now possible to create floating links between HDOCs and arbitrary web pages. These pages are parsed locally and converted into HDOCs. There are two types of parsing:
Regular parsing is for everyday use. It lets you download web pages in a readable format, but it’s not suitable for creating floating links. In fact, I’ve disabled viewing floating links on such documents when the main HDOC (that contains floating links) is downloaded from the web. You may still view floating links when connecting to your locally created documents to HDOCs created with regular parsing.
Deterministic parsing uses a special notation in the URL (after the # sign) to specify exactly how a document should be parsed. This ensures that readers always see a page parsed exactly as intended, with no broken floating links caused by differences in how client apps handle parsing.
Deterministic parsing may require some extra work and, in some cases, may not be possible to use. That’s why, for casual reading and downloading, I use text-density-based regular parsing instead.
WordPress Trick
I’ve also implemented a trick that allows the system to use the WordPress API for WordPress sites (about 40% of the web). This produces a deterministically parsed document that can even include a comments section with paginated loading.
UPDATE (December 25, 2025): I removed WordPress trick. It seems too hacky. I may add it later if I change my mind.
JSON Format for Comments in HDOCs
Speaking of comments — I’ve added a new JSON format for them. In fact, I suggest using the same format WordPress uses, but universally across all websites. If it works well for 40% of the web, it should work for the rest too. In the future, I plan to add visible connections between comments and the main text of each article.
Embedded HDOCs
I’ve also introduced embedded HDOCs. Originally, HDOCs were meant to be served from separate URLs, distinct from the original page URLs. But then I realized — why create extra endpoints? Instead, we can embed JSON containing all the necessary information directly in the page, marking the content with a special class. The client app can then construct the HDOC locally, while keeping the original appearance exactly as the author intended. This way, each article only needs a single URL.
Standalone HDOCs are still supported by the app. WordPress plugin only serves them if the original page is disabled.
Browser Extension
I didn’t mention it in my “Plans for 2025” article, but I always knew I’d eventually build a browser extension to make it easier to collect links, images, and documents from the browser into the app. So — I built it.
Dropping sw:// and sws:// URI Schemes
Before the app gets any users, I decided to drop the custom URI schemes. Originally, before the extension existed, I thought users without it would need a way to send HDOCs from the browser into the app — hence the custom schemes. But now, the extension makes that unnecessary. It’s too convenient not to use, and it handles all data transfer between the browser and the app without any custom URI schemes.
Extension Instead of Browser (change of plans)
In my “Plans for 2025” article, I mentioned that I was planning to create a browser that supports the new data formats. But recently, I decided it makes more sense to add that functionality to my existing browser extension instead.
First, this approach means I don’t have to compete with existing browsers. Second, with the introduction of embedded HDOCs, the extension can now detect them and simply replace the original page with the HDOC version.
For loading additional pages, the extension will connect to the LZ Desktop app, which will act as a proxy server. Since browser pages can’t directly make requests to arbitrary websites, the desktop app will help work around that restriction.
Correction: extensions can actually make requests to arbitrary pages, so a proxy server won’t be needed (November 4, 2025).
So that’s just a change in my plans. I haven’t yet implemented this functionality in the extension.
Other Improvements
There are many other smaller changes I’ve made to the project, which I won’t go into here.
Lately, I’ve been thinking about the Static Web (Web 1.1) and why it allows us to have visible connections, while the current Web (Web 2.0) doesn’t. And I realized that in my very first post — Web’s Biggest Problem. Introduction to Web 1.1— I completely misdiagnosed the issue.
My Initial Misdiagnosis
I made it sound like the problem is that all content on the Web is locked up in different containers. But that’s not really the issue if what you want is visible connections between web pages.
Yes, the code in the “jail cell” can’t make requests to arbitrary servers. Because of that, you can’t just grab a page from another website, place it next to your own, and show visible connections between the two texts.
They were able to show multiple pages side by side with visible connections between them because all those pages were loaded from the same website. If they had tried to load a page from another website, it wouldn’t have worked.
Why That Approach Wouldn’t Work
But even if it were possible to load pages from different websites, what kind of solution is that? To connect texts on two arbitrary pages you’d have to go through some special site that makes it happen? That’s a strange workaround if your goal is to bring visible connections to the Web.
This is why browser cross-domain restrictions aren’t the real problem.
The Role of Browsers
The functionality of visible connections should be built into client apps like browsers, not individual websites.
So the real question is: can browsers present two regular HTML pages side by side and show visible connections between them? The answer is… yes. Technically, it’s possible.
Yes, web pages run in separate containers, but the main process and those containers can exchange messages. The main process can also inject JavaScript into pages. At least if you are going to develop your browser using Electron, these capabilities are available.
The solution would be complex, with a bunch of moving parts to coordinate. But the bottom line is: it’s possible for browsers to display visible connections between normal pages.
Why Browsers Don’t Do It
Imagine two web pages side by side, each taking half the screen. In many cases, this arrangement would be awkward:
Pages have headers, footers, menus, and ads that eat up space.
Some layouts force horizontal scrolling just to see where the connection line goes.
Pages with active code may change unpredictably as you read.
So, while it would work for some pages, for many it would look clumsy. And on constantly changing pages, it wouldn’t work at all.
Too Much Freedom Inside the “Jail Cell”
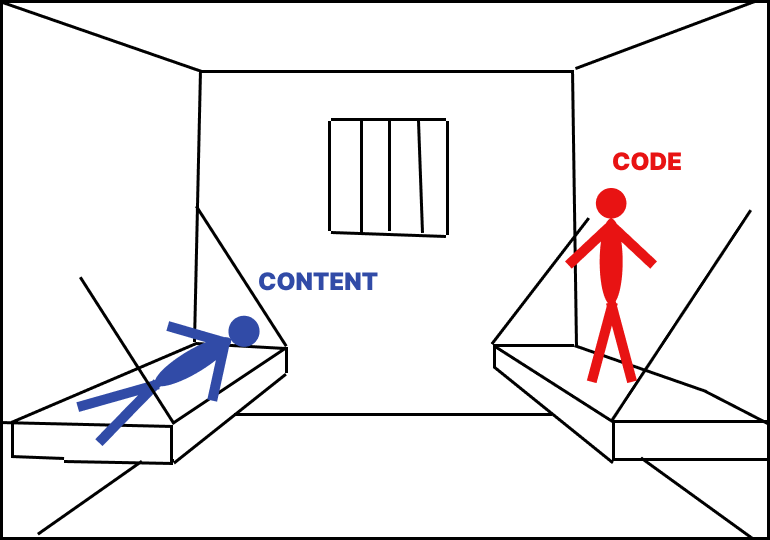
Here’s the surprising twist: the Web’s biggest problem isn’t that content is locked inside “jail cells” — it’s that inside those jail cells, content has too much freedom.
There is no standardized layout for a web page. And the presence of code makes content unpredictable.
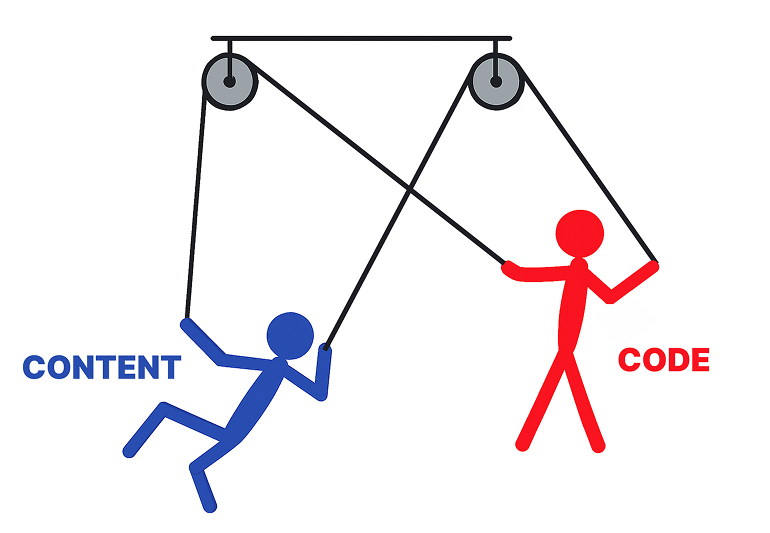
Think of the content and code as two guys locked in a cell together like on the image above. But imagine them dancing together kind of like in the movie Swiss Army Man the main character danced with a corpse using ropes to move the corpse like a puppet.
Remember, the content on its own is paralyzed but the code can make it change unpredictably.
And even without code, web page layouts are unpredictable. Some are simply too strange to reliably support visible connections.
The Real Issue
The challenge I’m trying to solve is how to bring visible connections to the Web. The main reasons it hasn’t happened yet are:
CSS makes visible connections awkward.
JavaScript makes content unpredictable.
Yes, because of the code the content is locked up in containers — but that’s not the real problem. The real problem is the lack of a standardized web page.
Why Standardization Matters
Currently, what’s standardized on the Web are the languages: HTML (markup), CSS (styling), and JavaScript (scripting). The idea is that the same code produces the same result in different browsers. But the actual look and structure of the page are entirely up to the author.
Inside your page, you have total freedom.
HDOC, on the other hand, removes that freedom. It enforces a standard layout: one column of text, plus standardized navigation panels that you fill with content but don’t style. No scripts are allowed.
This makes HDOC predictable. And because of that predictability, visible connections will almost always work and look good.
Conclusion
The biggest problem of the Web is not containers, not cross-domain restrictions — but the lack of a standardized page structure. Without it, visible connections remain unreliable. With it, they could finally become possible.
Here you’ll find a few examples of documents that use visible connections. Their purpose is simply to show the new capabilities now available to you. On their own, these examples aren’t particularly useful.
In the near future, I’ll try to create materials that are useful, and I’ll also try to encourage others—mainly teachers and other educators—to create their own materials that make use of visible connections.
First example: a page connected to two other pages on other websites
Open this page and scroll until you see highlighted texts. Click on them and the secondary documents will be loaded. You will see visible connections.
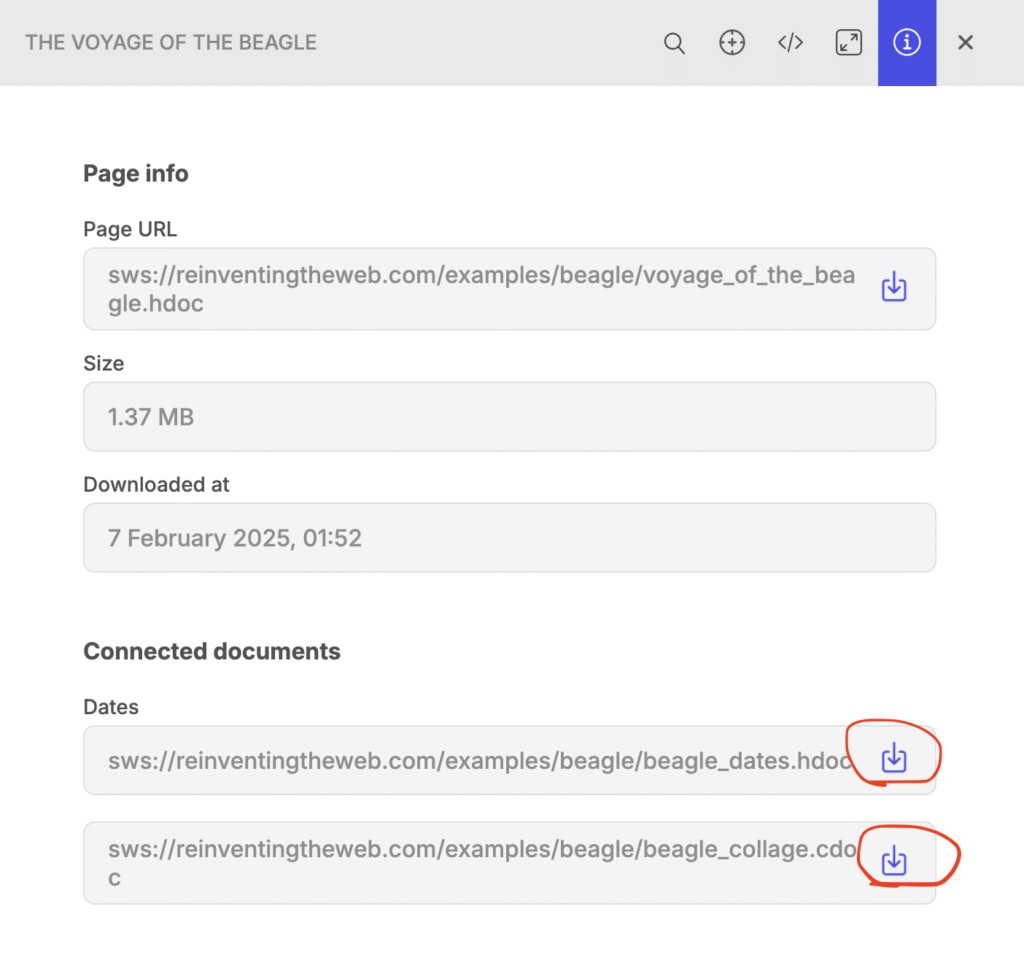
Second example: a page from another site connected to two other pages.
Open this page. Click “download all connected documents” button that is located in the top right corner of the window. What’s interesting about this document, is that the main text (the book) is actually fetched from another site.
Third example: a page connected to a page on another website
Now you can open the same examples in the browser and then download them into the app using the extension. Open extension’s popup and click “Download” button.
In the app you download each connected document individually.
Here is an AI-generated podcast I created using the articles I have on this blog so far.
There are some minor mistakes that I mentioned in the video’s description. Overall it’s a good intro to my ideas about the new Web that can be built in the near future.
add backup options to LZ Desktop (right now, backups have to be created manually) (done in June)
add multiple worlds to LZ Desktop (a world is a zoomable square where you organise your content).
add all the missing functionality and fix bugs in LZ Desktop
create a web browser (a separate desktop app) that supports both regular (Web 2) pages and new static pages (HDOC, CDOC, SDOC) (released a browser extension in November instead.There are no more plans to create a browser.)
add an option to integrate Google Analytics with the Static Web Publisher plugin
promote Static Web Publisher plugin so that by the end of this year we could have a list of hundreds of websites that support Web 1.1
Crowdfunding this project
I need about a year—maybe less—to accomplish these goals. The problem is, I don’t have enough money to keep working on the project full-time.
I started this project in late November 2023. Initially, I worked on it while taking on freelance jobs, but by summer 2024, my workload became overwhelming, forcing me to pause development for a few months. Since October 2024, I’ve been on a sabbatical, working on this project full-time. I’m burning through my savings, and that can’t go on forever.
So, I’ll try crowdfunding. I need about $600 per month to cover basic expenses.
Why you should consider donating
If I don’t get enough funding, I’ll have to take on freelance work within a month or two. I’ll try to keep developing this project on the side, but realistically, there will be huge gaps in progress. What could take a year might end up taking years. Worse, the project might never properly launch if I can’t dedicate enough time to it.
Another risk: now that I’ve put the idea of Web 1.1 out there, others might jump in and start developing their own software. This could lead to a mess of incompatible standards—which is the last thing we need. At least in the beginning, until all the new data types are well-defined, you don’t want to have too many cooks in the kitchen.
So, it makes sense to crowdfund my project and complete it as fast as possible, as delays can lead to bad outcomes.
Can I commercialise this project?
Eventually, I may explore ways to monetize services built around this project. For example, I could offer seamless content transfer from a mobile phone to a user’s zoomable desktop, or streamline content sharing between users. Instead of exporting content to a file and emailing it, you could send it directly from the app, and it would appear in your friend’s app. These are features I could integrate into LZ Desktop.
A Xanadu-like publishing platform, also discussed in the same post.
These ideas, however, are a bit more ambitious.
The main issue with commercialising the project right now is the lack of users. Any early attempts at monetization would be a distraction—I’d spend too much time setting things up without generating meaningful revenue.
At this stage, crowdfunding is the most viable way to sustain the project, at least for the first year.
How to donate
Currently, I don’t have any payment methods configured. I will first start discussions about Web 1.1 on different forums. Then, if I see positive feedback, I’ll think about the ways to accept donations. So, stay tuned.
You may have noticed, that URLs for accessing content on Web 1.1 start with sw:// or sws:// instead of http:// or https://.
What is the reason for having those new URL schemes?
First of all, sw:// stands for “Static Web”. And sws:// means “Static Web Secure”. There is no special protocol behind those URL schemes. Instead, every time you make a request, the client app automatically replaces sw:// with http:// and sws:// with https:// in the URL, before making that request.
Having new URL schemes serves a couple of purposes:
You can visually distinguish static from non-static content.
URL schemes help client apps decide which app should handle each specific piece of content.
To better understand why new URL schemes are needed, let’s look at the following schemes.
Client web software as it is now
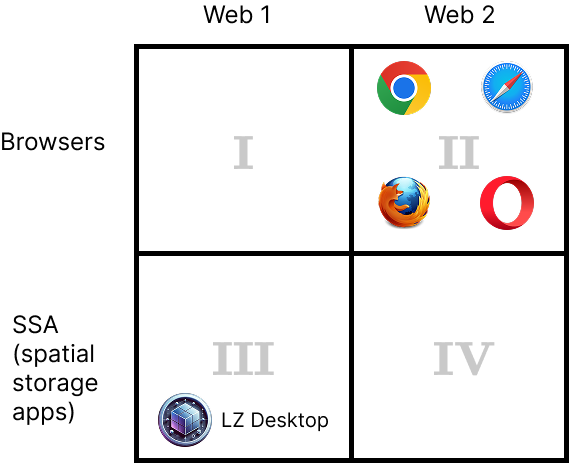
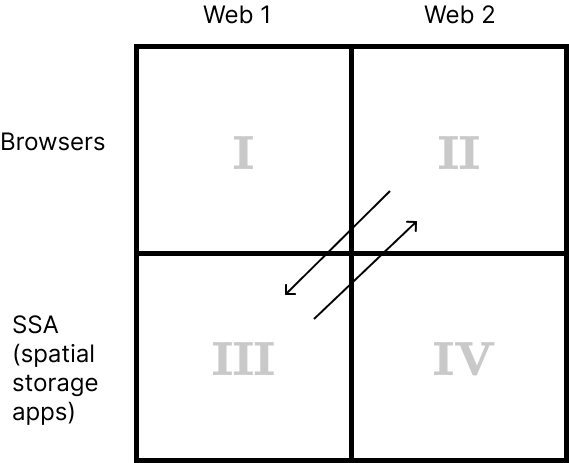
Web 1 (I use terms Web 1 and Web 1.1 interchangeably) consists of static web pages of the new types (HDOC, CDOC, SDOC). Web 2 consists of regular HTML pages, which may contain CSS and scripts.
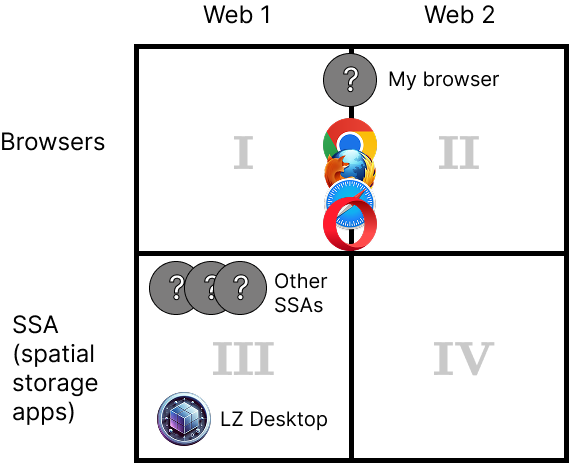
Currently, you use regular browsers to view Web 2 pages (quadrant II) and LZ Desktop to view static web pages (quadrant III) which you have to save on your zoomable desktop first.
We don’t have any software that would work in quadrant I yet. And quadrant IV is not very important right now. Its only use currently is this: an HDOC can have an associated Web 2 page on its side which you can load in LZ Desktop. So, you can say that LZ Desktop operates in quadrants III and IV. In the future quadrant IV will also be used for other, technical, reasons, like authentication, to get Web 1 content that is accessible only to authenticated users.
If you want to save a Web 2 page in a spatial storage app (SSA), you would be saving a URL of that page. An SSA can be developed that also shows you Web 2 pages, but that would be like merging an SSA and a regular browser, which doesn’t make much sense, since you can instead jump from SSA to your regular browser to view your Web 2 page.
For the purposes of our current discussion quadrant IV may be ignored.
How you navigate the Web now
Currently you can jump between quadrants II and III using URL schemes. If you browse Web 2 in your regular browser and click a link that starts with sw:// or sws://, the URL will be passed to LZ Desktop where the content will be loaded.
And vice versa: if you click a link in LZ Desktop that starts with http:// or https://, that link will be opened in your default browser.
Client web software in the future
In the near future I plan to develop a browser that supports both regular web pages (Web 2) and static web pages (Web 1). That browser will operate in quadrants I and II. In a more distant future, when a lot of websites support static data formats (HDOC, CDOC, SDOC), mainstream browsers will also start supporting those formats. At least that is the goal.
Also, other SSAs may be developed by other people and companies.
How you will navigate the Web in the future
In a browser that operates in quadrants I and II you navigate between Web 1 and Web 2 seamlessly. Under the hood, Web 1 and Web 2 pages are loaded differently but from a user’s perspective, when you click a link, you either load a new page in the same tab or a new tab is opened, depending on ‘target’ attribute of the link.
When viewing a Web 1 page, somewhere in the interface of your browser there will be a Save button. By clicking it you pass the entire document from your browser to your SSA. In other words, you navigate from quadrant I to quadrant III. That mechanism is not yet implemented. We will also, probably, need a mechanism to pass a document from SSA to a browser (from quadrant III to quadrant I).
You may still need to be able to pass some links to Web 2 pages you find in your SSA to your browser (navigation from quadrant III to quadrant II).
An alternative to using SW and SWS links
Introducing new URL schemes is generally discouraged unless necessary. Can we manage without them? The alternative to using new URL schemes would be to always use http:// and https:// links for all types of content. The browser or SSA would then determine how to handle the content based on its Content-Type.
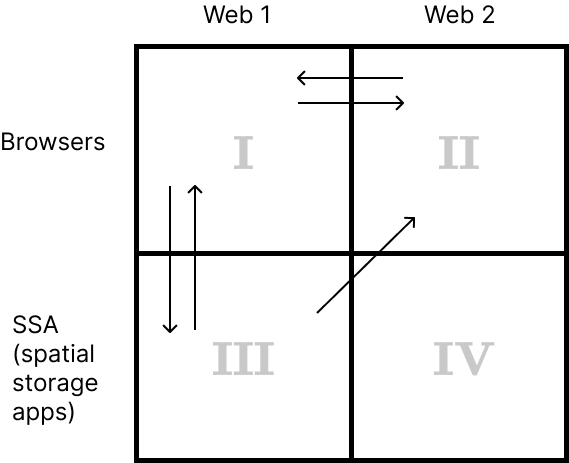
To see if this alternative is convenient, we need to keep in mind navigational diagrams, both for present Web and the future Web. Refer to the two diagrams from above that have arrows.
Let’s look at different navigation scenarios in present day Web and in the future Web, using only http:// and https:// links.
Present day Web
If you need to go from quadrant II to quadrant III, you click on the link in your regular browser that doesn’t know anything about Web 1.1. Since the link is just a regular http link, your browser will either download the content as a file, or show you the source code in a tab. That is not how we want to view a Web 1 page.
To actually load the content in LZ Desktop, you’d have to copy link address and paste it in the sliding panel in LZ Desktop. Super inconvenient.
We may create a browser extension that opens LZ Desktop when you click on certain links, but then we’d need to mark those links somehow, probably by giving them a special CSS class name. Who’s going to do it for every link that leads to static data types?
Second scenario: going from quadrant III to quadrant II. If you are in LZ Desktop and you click some link, the app must determine if the link leads to Web 1 content or Web 2 content. We can make a request, and examine the content type in the response. If it is Web 1 content, we open it in the app. If it is Web 2 content, we pass the URL to the default browser. In this scenario we would be making the same request two times: first in LZ Desktop and then in the browser.
To avoid double requests we can make users mark links manually as Web 1 or Web 2 links. But that’s annoying and error-prone.
Future Web
In the future Web you navigate between quadrants I and II inside your browser. In this case, if all links are http:// or https:// links, the browser will determine data type of downloaded content. If it’s a Web 2 page, the content will be injected into a webview. If it is Web 1 page, it will be loaded without using a webview.
So, in this future case you don’t need sw:// and sws:// links.
To navigate between quadrants I and III a different mechanism will be used. New URL schemes are not needed here as well.
There is also a case of navigating from quadrant III to quadrant II. If your SSA forwards every link into your browser then new URL schemes are not needed here as well, assuming all browsers in the future work with Web 1 and Web 2. But there may be different types of SSAs. Imagine an app that only works with Web 1 pages, and sends Web 2 links to a browser.
In short, there are different possible apps in the future. Some SSAs may still need to distinguish between Web 1 and Web 2 pages. You do it either by making the user mark links which is a very poor user experience, or by using different URL schemes. In this case the website owner has to decide which URL scheme to use. But this decision is often automated by the software on the backend.
Considering All Phases of Web Evolution
Even if we were convinced that in the future all browsers would have spatial storage functionality, so that one app would cover all 4 quadrants, avoiding the need for new URL schemes, what about the present day Web? Currently you have to use two different apps: a browser for navigating the Web, and LZ Desktop for saving content. I worry that if we only use http:// and https:// URL schemes, the navigation between apps would be so inconvenient, that it could negatively affect the adoption of the new data types.
Final Thoughts on URL Schemes
I’ve spent a lot of time thinking about how best to handle navigation between apps. While I’m not entirely convinced that introducing new URL schemes is the perfect solution, they do address key usability issues. Without them, early adoption of Web 1.1 could suffer due to poor user experience.