I actually decided to drop custom URL schemes eventually. They are no longer supported by my app, so the information in this article is outdated.
This page contains floating links.
To view them install Visible Connections extension and reload the page.
You may have noticed, that URLs for accessing content on Web 1.1 start with sw:// or sws:// instead of http:// or https://.
What is the reason for having those new URL schemes?
First of all, sw:// stands for “Static Web”. And sws:// means “Static Web Secure”. There is no special protocol behind those URL schemes. Instead, every time you make a request, the client app automatically replaces sw:// with http:// and sws:// with https:// in the URL, before making that request.
Having new URL schemes serves a couple of purposes:
- You can visually distinguish static from non-static content.
- URL schemes help client apps decide which app should handle each specific piece of content.
To better understand why new URL schemes are needed, let’s look at the following schemes.
Client web software as it is now
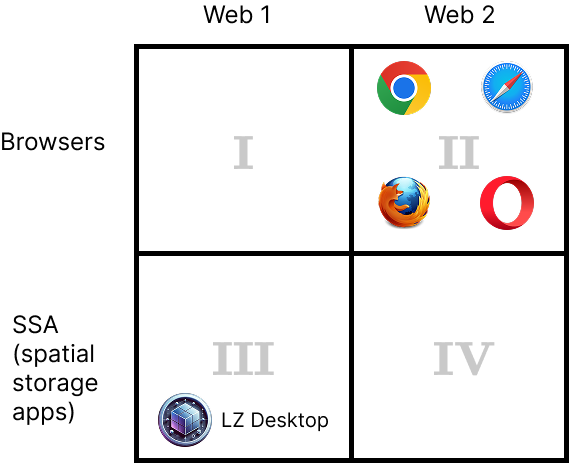
Web 1 (I use terms Web 1 and Web 1.1 interchangeably) consists of static web pages of the new types (HDOC, CDOC, SDOC). Web 2 consists of regular HTML pages, which may contain CSS and scripts.
Currently, you use regular browsers to view Web 2 pages (quadrant II) and LZ Desktop to view static web pages (quadrant III) which you have to save on your zoomable desktop first.
We don’t have any software that would work in quadrant I yet. And quadrant IV is not very important right now. Its only use currently is this: an HDOC can have an associated Web 2 page on its side which you can load in LZ Desktop. So, you can say that LZ Desktop operates in quadrants III and IV. In the future quadrant IV will also be used for other, technical, reasons, like authentication, to get Web 1 content that is accessible only to authenticated users.
If you want to save a Web 2 page in a spatial storage app (SSA), you would be saving a URL of that page. An SSA can be developed that also shows you Web 2 pages, but that would be like merging an SSA and a regular browser, which doesn’t make much sense, since you can instead jump from SSA to your regular browser to view your Web 2 page.
For the purposes of our current discussion quadrant IV may be ignored.
How you navigate the Web now
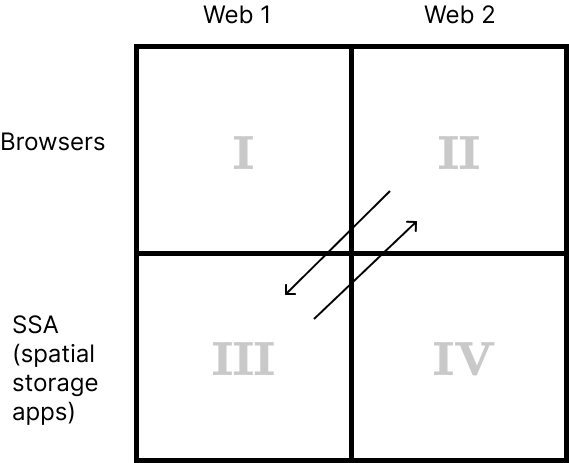
Currently you can jump between quadrants II and III using URL schemes. If you browse Web 2 in your regular browser and click a link that starts with sw:// or sws://, the URL will be passed to LZ Desktop where the content will be loaded.
And vice versa: if you click a link in LZ Desktop that starts with http:// or https://, that link will be opened in your default browser.
Client web software in the future
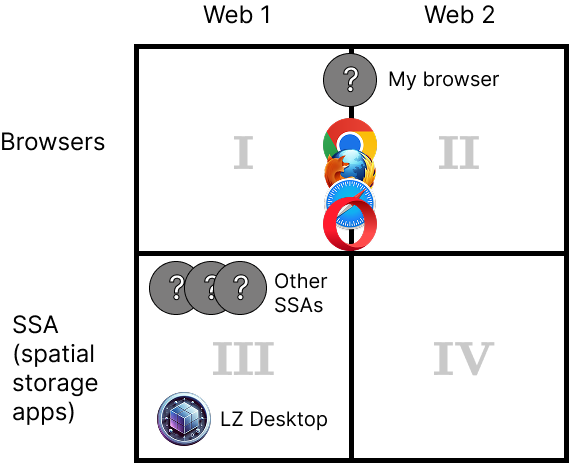
In the near future I plan to develop a browser that supports both regular web pages (Web 2) and static web pages (Web 1). That browser will operate in quadrants I and II. In a more distant future, when a lot of websites support static data formats (HDOC, CDOC, SDOC), mainstream browsers will also start supporting those formats. At least that is the goal.
Also, other SSAs may be developed by other people and companies.
How you will navigate the Web in the future
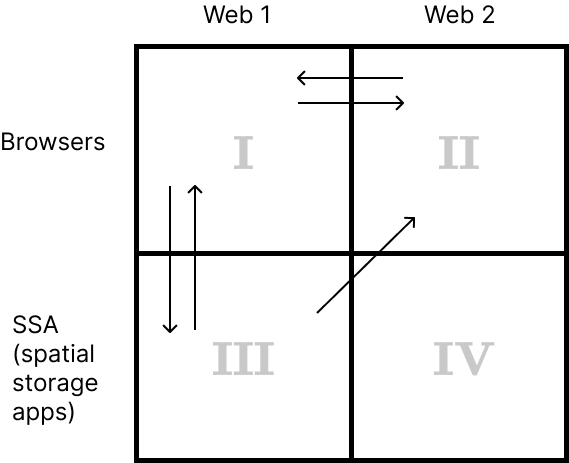
In a browser that operates in quadrants I and II you navigate between Web 1 and Web 2 seamlessly. Under the hood, Web 1 and Web 2 pages are loaded differently but from a user’s perspective, when you click a link, you either load a new page in the same tab or a new tab is opened, depending on ‘target’ attribute of the link.
When viewing a Web 1 page, somewhere in the interface of your browser there will be a Save button. By clicking it you pass the entire document from your browser to your SSA. In other words, you navigate from quadrant I to quadrant III. That mechanism is not yet implemented. We will also, probably, need a mechanism to pass a document from SSA to a browser (from quadrant III to quadrant I).
You may still need to be able to pass some links to Web 2 pages you find in your SSA to your browser (navigation from quadrant III to quadrant II).
An alternative to using SW and SWS links
Introducing new URL schemes is generally discouraged unless necessary. Can we manage without them? The alternative to using new URL schemes would be to always use http:// and https:// links for all types of content. The browser or SSA would then determine how to handle the content based on its Content-Type.
To see if this alternative is convenient, we need to keep in mind navigational diagrams, both for present Web and the future Web. Refer to the two diagrams from above that have arrows.
Let’s look at different navigation scenarios in present day Web and in the future Web, using only http:// and https:// links.
Present day Web
If you need to go from quadrant II to quadrant III, you click on the link in your regular browser that doesn’t know anything about Web 1.1. Since the link is just a regular http link, your browser will either download the content as a file, or show you the source code in a tab. That is not how we want to view a Web 1 page.
To actually load the content in LZ Desktop, you’d have to copy link address and paste it in the sliding panel in LZ Desktop. Super inconvenient.
We may create a browser extension that opens LZ Desktop when you click on certain links, but then we’d need to mark those links somehow, probably by giving them a special CSS class name. Who’s going to do it for every link that leads to static data types?
Second scenario: going from quadrant III to quadrant II. If you are in LZ Desktop and you click some link, the app must determine if the link leads to Web 1 content or Web 2 content. We can make a request, and examine the content type in the response. If it is Web 1 content, we open it in the app. If it is Web 2 content, we pass the URL to the default browser. In this scenario we would be making the same request two times: first in LZ Desktop and then in the browser.
To avoid double requests we can make users mark links manually as Web 1 or Web 2 links. But that’s annoying and error-prone.
Future Web
In the future Web you navigate between quadrants I and II inside your browser. In this case, if all links are http:// or https:// links, the browser will determine data type of downloaded content. If it’s a Web 2 page, the content will be injected into a webview. If it is Web 1 page, it will be loaded without using a webview.
So, in this future case you don’t need sw:// and sws:// links.
To navigate between quadrants I and III a different mechanism will be used. New URL schemes are not needed here as well.
There is also a case of navigating from quadrant III to quadrant II. If your SSA forwards every link into your browser then new URL schemes are not needed here as well, assuming all browsers in the future work with Web 1 and Web 2. But there may be different types of SSAs. Imagine an app that only works with Web 1 pages, and sends Web 2 links to a browser.
In short, there are different possible apps in the future. Some SSAs may still need to distinguish between Web 1 and Web 2 pages. You do it either by making the user mark links which is a very poor user experience, or by using different URL schemes. In this case the website owner has to decide which URL scheme to use. But this decision is often automated by the software on the backend.
Considering All Phases of Web Evolution
Even if we were convinced that in the future all browsers would have spatial storage functionality, so that one app would cover all 4 quadrants, avoiding the need for new URL schemes, what about the present day Web? Currently you have to use two different apps: a browser for navigating the Web, and LZ Desktop for saving content. I worry that if we only use http:// and https:// URL schemes, the navigation between apps would be so inconvenient, that it could negatively affect the adoption of the new data types.
Final Thoughts on URL Schemes
I’ve spent a lot of time thinking about how best to handle navigation between apps. While I’m not entirely convinced that introducing new URL schemes is the perfect solution, they do address key usability issues. Without them, early adoption of Web 1.1 could suffer due to poor user experience.